ENGINEERING
DEVELOPMENT LIFE CYCLES
by Karl E. Wiegers
We've been taking a close look at the different tasks involved in a modern software-development project from the perspective of contemporary software-engineering methodology (some may say "theology"). My thrust has been that a systematic, structured approach to your software development efforts will pay off in a more durable, robust and maintainable product that more closely matches the customer's needs, compared to a traditional program-development approach. The ultimate definition of successful software is that it is delivered on time, comes in on budget and correctly satisfies the user's actual needs. I'm convinced that software engineering holds the promise of meeting these goals.
So far, though, we've only considered one possible sequence of software-development tasks. The method I've been describing is sometimes called the "waterfall" method of software development. The waterfall method is commonly used for the process-oriented systems I've described, such as my chemistry game, Reaction Time. However, it is by no means the only methodology available for creating a software application. Today I'd like to explore some alternative "models" or "paradigms" for software development.
These various development models are sometimes called "software life cycles," although these cycles aren't the same as plant and animal life cycles, in which birth leads to growth, to maturity, to birth again and finally to death. With software, the "birth again" step is generally omitted. And if you're too late delivering the goods, death may appear without the intervention of growth and maturity!
These different models do have some features in common. After all, software-systems engineering must always involve some gathering of user requirements, design of the system to be constructed, construction, testing of the system and its components, and ongoing project management, documentation and quality-assurance activities. And it's a safe bet that any system, no matter how it was built, will require some level of maintenance and change during its lifetime. The paradigms differ mainly in the timing and repetition of these activities.
Pre-Software
Engineering
In the olden days, a project often began with a
rather fuzzy notion of the goal. Some time was spent on planning or
design, and then a larger block of time was devoted to writing code.
Coding was followed by an infinite loop of testing and debugging,
testing and debugging. The testing phase generally was declared to be
over when the delivery deadline had come and gone and the customer was
beating on the developer's door. We might summarize this historic
approach as a "code-and-fix" development technique.There were some obvious deficiencies with this strategy. First, the customer's involvement was too frequently limited to an initial interview or two, followed (after a sizeable delay) by a presentation of the "final" product, which often bore little resemblance to what he had in mind. Second, insufficient time devoted to system design at both the overview and detail levels meant that things often went awry during coding. The problems were amplified when more than one person was involved with the actual programming. Working without a master plan is a recipe for communication problems. Third, the ad hoc testing approaches left a lot of bugs lurking in the system, awaiting discovery by irate users. And fourth, the lack of structure in the system design, combined with patches placed on code during debugging and the generally inadequate documentation, made system maintenance a nightmare.
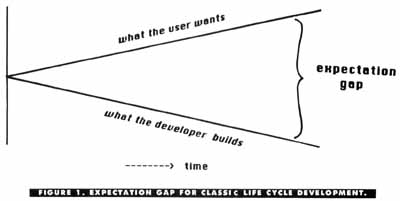
Figure 1 graphically illustrates one consequence of this classic life cycle. As time goes on, the developer's impression of what the user wants and the customer's actual expectations tend to diverge. The bigger the gap, the lower the perceived quality of the final system by the user. More modern development methods are intended to reduce this expectation gap. The goals are to have faster and more accurate development of the correct software system.
The
Waterfall Model
The waterfall model for software development is
essentially a more disciplined variant of the classic life cycle. This
is the development method I've been describing over the past several
months. Basically, the waterfall model consists of several discrete
phases, each of which has specific deliverables (products) that must be
completed and approved before proceeding to the next step. These phases
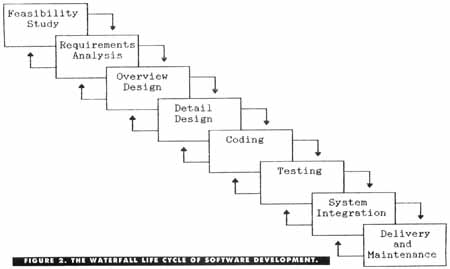
go by various names; one set of labels is shown in Figure 2 (I've seen
at least four published variants of this diagram, so I made up a
fifth). Sometimes you'll hear of "system specification" instead of
"requirements analysis," or "implementation" instead of "coding," but
the ideas are the same.If you've been reading this software-engineering series all along, you'll recognize the pieces of the diagram in Figure 2. Notice that each phase involves some feedback to the previous phase (the upward-flowing arrows). This reflects the fact that defects become detected as work goes on, and the defects usually are attributable to errors made in an earlier phase. The best way to handle these problems is to backtrack to the source of the error and correct it there, rather than simply slapping a patch on it at the later stage when the problem showed up. For example, a single error at the requirements phase may lead to several problems during design, so your best bet is to go back and fix the underlying requirements flaw before continuing with design.
The waterfall method also differs from the classic life cycle by using a variety of techniques to improve quality and productivity in each phase. Requirements-analysis benefits from the data-flow (DeMarco) methods used for structured specification. Data-flow techniques also are valuable in high-level design (Yourdon, and Gane and Sarson methodologies). Module-level design is facilitated using structured English (pseudocode) or action-diagram techniques, among other diagramming methods. Structured programming methods lead to code that is readable and maintainable. Structured testing procedures (both white-box and black-box) prevent many errors from seeping through. Quality-assurance activities, such as structured walkthroughs, should be performed before proceeding to the subsequent phase. And many computeraided software engineering (CASE) tools are available to automate some of these tasks. We've discussed all of these ideas in earlier articles in this series. The key word throughout is "structure."
From the quality perspective, managing a project being developed under the waterfall method poses particular challenges. Because of the sequential flow of tasks, it's important to build in high quality from the very start. It's difficult to go back and retrofit quality after a program has been completed. The quality of the code depends upon that of the system design, which in turn depends upon the quality of the specifications, and so on. One way to manage this is to break each phase of the project into separate substeps, with a checkpoint quality review scheduled at the end of each substep. You don't continue with the project until each subphase meets its goals. This subdivision is the basis for some software project management methodologies, which we'll discuss in a future installment.
One problem with the waterfall approach is that the customer doesn't see any usable products until near the end of the development effort. I've found it valuable to review the specifications and perhaps even the system design with the customers, but this isn't the same as letting the user get his grubby paws on a keyboard. A long time lag between inspiration and delivery can reduce the customer's interest in, or need for, the system, as well as lead to a bigger gap between what he wants and what he gets, as we saw in Figure l.
Another drawback to the waterfall life cycle is the need to lock the system requirements once the analysis phase is complete. Of course, in real life, it's rare that requirements are truly frozen. However, due to the long sequence of steps between concept and completion, any changes requested by the customer, once design is under way, have repercussions throughout the systemdevelopment effort. It's difficult enough dealing with errors that are found at later stages of development, let alone coping with volatile requirements. This is a particular problem in dynamic technical environments, such as the scientific research organization I work in. Since system requirements often do change as time goes on, the software developer needs a better way to cope with this.
Iterative
Prototyping
Iterative prototyping is an alternative
software-development approach that aims to avoid some of the
deficiencies of the waterfall method. This model addresses the problem
of having incomplete or uncertain specifications at the beginning of
the project, as well as coping with anticipated changes in the specs
during the time needed for development. Prototyping tends to be a
user-driven development method, rather than the prespecified approach
characterized by the waterfall paradigm. Prototyping is less formal and
more dynamic, involving continuous incremental change as the user's
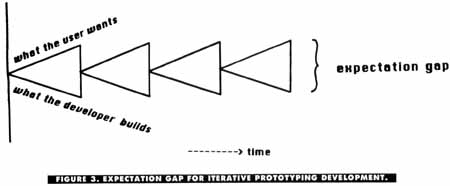
needs become more precisely defined.Human beings find it easier to critique than to create. The idea behind software prototyping is to get something into the customer's hands quickly as a first cut, so the user can tell you whether or not this is what he has in mind. Revising the prototype leads to an interim product that more closely meets the user's needs. By repeating this prototype-review-modify cycle as many times as necessary, the divergence problem illustrated in Figure 1 is reduced to something like that shown in Figure 3. I've found that frequent iteration with the customer is vital to success, even when I'm not following a true prototyping life cycle.
When the developer delivers something that closely matches what the user has in mind, the user's perception of system quality is greatly increased. The prototype aids the effort by serving as a vehicle to help gather and refine the system requirements, as well as being a preview of things to come.
The main idea behind prototyping is speed. Users always change their perceptions of what they want after using a new system for a while. If the new system can be constructed and modified quickly, we developers can do a better job of uncovering the ambiguities, inconsistencies, misunderstandings and omissions that plague conventional system-specification efforts.
A prototype can be either a mock-up or a working model of the ultimate system being constructed. A mock-up consists of sample screens and reports, with limited functionality built in. You may write enough code to let the user move from screen to screen in a logical way and enter representative data, but the brains behind the screens are either absent or faked. Such a system has been called a "vacuous prototype." It's valuable for simulating a user interface, but it doesn't do any useful work. For a system that is user-intensive, this can be a valuable way to help the user evaluate whether the "look-and-feel" of the system you propose to build will suit his wishes.
A working-model prototype might consist of a full implementation of just part of the system. There may be just a few screens and one sample report, but with the code to convert inputs into outputs fully functional for that limited subset of the system. This kind of prototype will let the user see if he is comfortable with the approach you propose, and since it actually does useful work, you may be able to incorporate the working model into the final system.
Notice that this iterative method doesn't draw sharp lines between the development phases, as the waterfall method did. You can do a little requirements gathering, a little design, a little implementation, a little testing and a little delivery. Then, based on feedback from the customer, you do a little more requirements gathering, a little more design and so on. You continue with the iteration process until either: (a) you've reached a point where you can now write the actual, deliverable system quickly and accurately, or (b) the final prototype is the deliverable system.
Most computer systems don't have specific tools to facilitate prototyping, although more are appearing all the time. A softwareprototyping environment might include a screen painter, a report generator and some kind of interpreted language to let you hook the pieces together into a running system. The screen painter lets you quickly design screen displays and write enough code to let the user display them and move from one to another. The report generator can produce printed reports or screen displays from specifications without writing huge amounts of line-by-line print-formatting statements. Often you can use default-printout formats to get some output quickly and let the user then fine-tune the layout for complete implementation at some later time.
The interpreted language lets you display screens, do some actual processing and produce output. Interpreted languages often lack some of the rigor of their compiled brethren (like insistence on declaring all variables before using them), and they don't need the compile and link steps before execution. Hence, it's faster to write and try working code with an interpreter. Since computational efficiency is not paramount for a prototype, the fact that interpreted languages execute more slowly than compiled languages is not a concern. Also, interpreted languages often have excellent debugging facilities, which can facilitate quick turnaround in response to user complaints.
But what happens when you've reached the last iteration in the prototyping sequence and the customer is happy with the current status? You could simply say, "Okay, here it is; I'm done." But if you've written the code in an interpreted language, the performance at that stage may be inadequate for a production system. Also, you've probably neglected code documentation since you've been working on "just a prototype." The customer may not recognize the difference between a working model and a finished product, which would contain all of the software quality-assurance characteristics that we build into our systems. A prototype may well have traded both quality and efficiency for the ability to quickly demonstrate desired system capabilities. If you don't redo the final prototype, you may wind up with these shortcomings as integral parts of the delivered software; this may or may not be a problem.
The alternative is to keep the screens, reports, user interface and algorithms from the prototype, but recode all the procedural routines in a more efficient language, such as C, COBOL or Pascal. Unfortunately, programs in such languages often are more costly to maintain than the simpler code generated in a prototyping environment. The choice depends on the application itself. It certainly can be aggravating to finally get the system just the way the user wants it, only to know that you have to rewrite much of it in another language before you're done. The saving grace is that the iterative-prototyping process, emphasizing as it does user involvement, has done a good job of pinning down the user's precise system requirements, so the recoding step should go quite smoothly.
Unfortunately, GEM doesn't lend itself easily to the prototyping model. Atari BASIC did just fine, as long as you worked within its limitations. Getting an application up and running in a full-screen windowing environment, like GEM or the Macintosh, takes quite a bit of effort; it's not something you throw together in a few hours just to see how your ideas might look and act. But software-engineering researchers (yes, Virginia, there are some) are actively pursuing the development of rapid prototyping tools for windowing environments. Patience, please, for a few more years.
Incremental
Development
Another software-development approach that can be
effective is incremental development. In this scheme, you begin with
the specifications for the first part of the target system and go ahead
and develop it using whatever methodology is most appropriate. Placing
a completed portion of the ultimate system into the hands of the users
quickly provides them with some real functionality while leaving
everyone more time to refine the specifications for the rest of the
system.Incremental development breaks the development project into a series of small individual projects that can be completed independently, each portion being appended to the parts you've already finished. The rapid turnaround between the customer's request and delivery of something useful reduces the usual gap between initial expectations and those that would prevail much later when the complete system otherwise would be delivered. This method also can reduce the time-dependent evolution of system specifications, which always seems to be one step ahead of a traditional development effort.
Obviously, not every project lends itself to incremental development. Some systems really have to be done as a massive whole that is integrated all at once. Another concern is that each sequentially completed portion of the system must link up nicely with the parts already in place. I've found this method to work well if a first cut at the overall system specification has been completed, so that we can intelligently partition the system into chunks that can be implemented individually. The detailed design of the subsequent pieces can wait until the first section has been fully implemented.
One danger with incremental development is that changes made in the specifications for the later parts of the system can result in the portions completed initially needing major revision or even being scrapped. On the other hand, it may turn out that the latter sections don't even have to be completed, due to the customer's experience with the part you finish first. It's hard to accurately predict how things will turn out with incremental development, but keep it in mind as an option for your next big project.
Fourth-Generation
Languages
One other methodology for system development
bypasses the traditional codewriting phase entirely, using what are
referred to as "fourth-generation languages," or 4GLs (sometimes more
generally termed "fourth-generation techniques," 4GTs).You're used to the traditional softwaredevelopment process using third-generation high-level languages like C, BASIC or FORTRAN. These "procedural" languages require the programmer to write in grim detail the instructions for each task performed in a program. We must individually manipulate each piece of data, handle all the screen-display interactions, define printout formats line by line, individually validate each user entry, handle the details of every file access and so on. The many lines of code required for all these functions lead to a major maintenance effort whenever a large system is enhanced or a bug eradicated.
Fourth-generation languages allow a "non-procedural" approach to certain domains of software development. A 4GL is often supplied as part of a relational database software package. (See the April '88 issue of ST-LOG for an informative introduction to relational databases by Frank Cohen.) Tools are provided to help implement the user interface and printed-output designs, and some kind of high-level language is available for communicating with the database. But you, both as developer and as user, are insulated from the nittygritty details of reading and writing files, performing basic arithmetic operations and writing all the code needed to handle complex screen displays.
At their best, 4GLs eliminate most of the tedious steps endured by the experienced applications developer. But this pot of gold doesn't come free. The main drawbacks of contemporary 4GLs (of which there are many) are that they are CPU hogs (computerese for saying that they execute inefficiently) and that they can be applied only to limited classes of fairly specialized applications. As I mentioned, these applications generally center about information stored in relational databases. Of course, a huge assortment of business applications fits in this very category, but the 4GL hasn't had much of an impact on scientific computing yet.
Not surprisingly, writing an application using a 4GL usually involves some programming, although at a higher level of abstraction than you see with a 3GL. Many fewer lines of code may be needed to perform a specific task using a 4GL. The most common language used for relational database accesses is called "Structured Query Language" or SQL (pronounced "sequel"). Rather than making you mess with opening files, reading records and so on, a query language like SQL lets you tell the computer what you want to do in Englishlike sentences.
Let's consider a simple example. Relational databases consist of two-dimensional tables containing rows and columns of information. Suppose you have a table called MAGAZINES, which lists all the magazines to which you subscribe (maybe you're a library). When you set up this table, you created columns with names like TITLE, COST, EXPIRATION DATE and THEME. Each row you add to the table would contain information for a particular magazine. ANALOG might be entered with a title of (guess what) "ANALOG", a cost of "$28," an expiration date of "8/90" and a theme of "Atari ST computing."
Imagine that you want to write a program to extract specific rows from this MAGAZINES table according to particular criteria, sort them in some way and display certain columns from the rows retrieved. Specifically, let's find the titles of all the magazines that contain the keyword "Atari" in the THEME column. You can probably imagine the many steps needed to do this in a language like BASIC. But in SQL, you'd write a concise program statement, such as: SELECT TITLE FROM MAGAZINES WHERE THEME CONTAINS "Atari." Note the close resemblance between this SQL statement and the English description of what we want to do.
This is not a tutorial on SQL, so we won't pursue it further. The main idea is that a query language like SQL lets the developer or customer do the conceptual work, while the computer handles the low-level stuff. Just because a 4GL is nonprocedural, doesn't mean there isn't any programming involved; it's just done at a higher level of abstraction. In fact, the SQL statements needed for elaborate queries from multiple tables in a large database can get horrifyingly complex.
There's some overlap of system tools between 4GL and prototyping environments. Both systems usually include a screen painter, which lets you quickly design a form on the screen to facilitate data entry by (or display to) the user, along with easily handling data validation and displaying help screens. Both systems often include a report painter and report-generator capability to easily lay out and produce even sophisticated printouts of information retrieved from the database. Some 4GLs involve a language for defining reports that looks suspiciously procedural to me. And a smart 4GL can actually generate the code automatically for many of the database accesses (queries and updates) you need to perform.
On the plus side, a 4GL environment can be a real asset for rapid system-development (for the right kind of system), and by removing much of the detailed code-writing, the maintenance requirements for a system built using a 4GL can be much reduced from those for a comparable system based on a 3GL. However, designing complex customized screens or writing complex queries can result in the same system developer's headaches we're used to from older technologies. And sometimes your system requirements may involve capabilities beyond those of a 4GL, such as graphics or heavyduty computations. Many 4GLs deal with this by providing ways to call a program written in a 3GL from within the 4GL environment. Does this average out to a 3.5-generation language?
One other advantage touted for the 4GLs is the goal of having much of the simpler applications development performed by the end user, rather than by a professional software developer. This is certainly a worthy goal in light of the serious work backlogs plaguing many software-development shops. While this may be possible with some current 4GLs, at least one of the most popular relational database systems available has a 4GL so complex (but powerful) that it turns my hair white. This may all be a clever ploy to provide permanent job security for the professional software developer.
Looking
Back
Today we've explored a variety of strategies for
developing applications software packages, including some interesting
alternatives to the traditional waterfall method. These techniques are
by no means mutually exclusive. Often you can benefit from a hybrid
approach: some initial analysis for a general picture of the problem,
followed by a little prototyping to get something into the user's
hands, then either incremental or full-blown waterfall development,
depending on how firm the requirements are when you're ready to start.The goal of each of these development life cycles is to meet our definition of highquality software as closely as possible. In case you've forgotten, high-quality software is delivered on time and on budget, and it meets the user's needs. The developer's challenge is to be able to share the customer's vision of the final system, then refine it (based on his own experience) for performance, ease of use and reliability. In future articles we'll talk more about software quality-assurance (making sure these goals are met) and software projectmanagement (mechanisms for meeting the goals).

Karl Wiegers, Ph.D., spent the '70s learning how to be an organic chemist, then spent the '80s wrestling with computers. He is now a software engineer in the Eastman Kodak Company photographic research labs. He hasn't yet selected a career for the '90s.