TEXT READABILITY ANALYZER
LOW OR MEDIUM RESOLUTION

by Tom Castle
The subject of text readability has been one of great interest and controversy among educators and publishers over the past 30 years. The interest in readability analysis comes from the concern about a specific audience's ability to understand a particular text. The controversy stems from a disagreement on just how to go about quantifying readability.
There are several factors involved in reading comprehension. Such items as sentence length and complexity, print size and quality, word recognition, writing style and subject appropriateness all contribute to the effective readability of a given text. Over the years, researchers have developed several methods to assign some value to the reading level of a particular text. Although the methods are generally simple, the criteria used for a given analysis are still fuel for heated debate.
Two of the analysis methods which use sentence length and word complexity as criteria for readability are Gunning's FOG and Flesch's methods of readability analysis. They are both fairly old methods. The Flesch method has been around since 1951; the FOG since 1968. Both methods seem to be highly regarded by educators and are often cited in the literature during discussions of readability.
These methods traditionally have been performed manually, but are quite amenable to computerization, reducing a day's worth of tedious manual calculation to only a few minutes. These analyses are available on a wide variety of microcomputers. For the Atari ST, Mark Skapinger's Thunder! spell-check program contains the FOG and Flesch analyses as one of the menu options. The method for calculating the FOG index listed in the appendix of Thunder! is incorrect however.
 ILLUSTRATION · JANET MARCH
ILLUSTRATION · JANET MARCH
Using the analyzer
The analyzer can be found on this month's disk under the name TXANAL.PRG. You can also create a copy of the program by typing and compiling the C source code shown in Listing 1. Listing 2 is an ST BASIC program that will create a copy of the resource file for the Text Readability Analyzer. This resource file must be in the same directory as the TXANAL.PRG program file when the program is run. To run the program, simply click on the file icon or filename from the GEM Desktop.
The Text Readability Analyzer uses the standard GEM features of drop-down menus, dialog boxes and file-selector boxes. To select a text file to analyze, choose "Analyze" from the file drop-down menu. A file-selector box set to the current drive and file path will be displayed. You can select a file from the current directory by typing a filename or scrolling through the directory. If you are in a folder and wish to proceed to the root directory of the current drive, click on the upper-left box in the file selector. You can also change the drive designation and path by clicking on the directory line of the file selector, backspacing over the unwanted characters, retyping a drive and optional path and clicking the "closer" box. Be sure to include the colon after the drive designation and back slashs between nodes in the pathname.
Once an analysis has begun, you should relax until final statistics are presented for the two indices. The mouse can be moved around but will not respond until the analysis is completed. After an analysis is over, another file can be selected from the file menu, or you can quit the program and return to the GEM Desktop.
Information you get
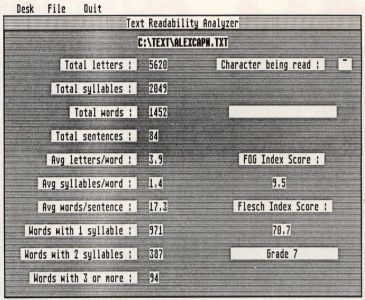
The analyzer will display various aspects of your text. You will get a word count of the document along with total sentence, syllable and letter counts. Mathematical averages are displayed for letters per word, syllables per word and words per sentence. The number of words containing one, two and three or more syllables is also given. Not all these parameters are necessary for calculating the FOG and Flesch Readability indices, but I thought as long as I had them, I'd share them.
The FOG and Flesch indices are given on the right-hand side of the screen. The FOG index is given as a school grade for the level of reading accomplishment to fully understand the text. The Flesch value is a scale from zero to 100. The Flesch levels are in increments of ten with the lowest reading level, Grade 5, as a score of 100 to 90. The school grade corresponding to a particular Flesch score is given under the score.
You should be aware that the results are not holy edicts, and they are not carved in stone. As mentioned before, there is a great debate surrounding readability analysis. Caution should be exercised when using this tool. It is meant only as a guide or approximation. Please don't use this on your eighth grader's history book, then run down to the school yelling that it was analyzed at only a sixth-grade level.
How it works
The mechanics of the Analyzer are quite simple. A file is read one character at a time. (Just to see if you passed the speed-reading course, I decided to display each character as it is read from the file.) If the character is alphabetic, it is placed in a buffer which also can be seen at the right-hand side of the screen. The buffer is built up with continuous alphabetic characters until a space or another non-letter character is encountered. Each letter encountered will increment the letter counter at the left.
Once a non-letter character is met, the contents of the buffer are parsed to determine how many syllables are contained in the word, if any. The number of syllables are counted and scored. The rules governing syllable parsing are simple. If three letters form the pattern of vowel/consonant/vowel, then the syllable is cut after the first vowel. If four letters form the pattern of vowel/consonant/consonant/vowel, then the syllable is cut after the first consonant. If four letters form the pattern vowel/consonant/consonant/ consonant, then the syllable is cut after the second consonant. Many times the syllables won't be partitioned correctly, but the partition will generate the proper number of syllables. The buffer is then cleared with the appropriate values being registered on the display.
Sentences are determined by the presence of periods, exclamation points and question marks. I had to add a few extra conditions to the existence of a sentence. This is because document files from word processors like 1st Word or Timeworks’ Wordwriter ST put a series of periods for tab markers and other format characters at the beginning of the file.
The analysis will keep churning through character by character until the end-of-file character, a Control-Z, is encountered. The data accumulated is then used to calculate the readability scores.
For programmers
The Text Readability Analyzer was written for the Lattice C compiler. I started to write it with Alcyon C, but the ease of using Menu + in conjunction with Lattice C is heaven. The thing to be aware of is that integers in Lattice C are 32-bit values. That is why I use the type WORD which is defined as a short integer, 16 bits, in the PORTAB.H file. You should also be aware that the Lattice C function fopen() returns a FILE pointer, not an integer file handle.
All the screen output is generated using the VDI call, v_gtext(), which accepts only strings as display arguments. The values displayed are converted to strings using the put__str() function found in the source code. All the math in the program is integer math. A function to perform rounding after integer division is given as dhv__round(). The decimal points are created by scaling tenfold prior to passing the value and number of desired decimal places to the put_str() function. That function also accepts a value to locate the string on the screen. Kill as many birds....
The parsing functions are not perfect, just traditional. You can improve them by adding more conditionals. For example, the parser presently splits three- and four-letter words with ending silent "e" into too many syllables. These words are fairly common, like "same," "tone," "axe," "make," "pile" and "eve." There are also words that end in the pattern of a vowel followed by "ous" that aren't parsed sufficiently. Some words that fall into this group are "punctilious," "fastidious," "continuous" and "notorious." If you thumb through Webster's, you're bound to find more exceptions.
There are also other types of analyzers that can be built. Many analysis methods depend on a list of recognized or common words. Simple strcmp() comparisons with a dictionary file could enhance an analyzer immeasurably. I omitted inclusion of such an analysis here since most of the word lists are between a few hundred and a few thousand words long. I've included a list of books and journal articles for those who are interested in further study of readability analysis.
Bibliography
Dufflemeyer, Frederick A. "Readability with a Computer: Beware the Aura of Precision." The Reading Teacher. January 1985, pp. 293-394.
Gilliand, John. Readability. London: Uni-books University of London Press, 1972.
Kennedy, Keith, "Determining Readability with a Microcomputer." Curriculum Review. November/December 1985, pp. 40-42.
Koenke, Karl. "Readability Formulas: Use and Misuse." The Reading Teacher. March 1987, pp. 672-674.
Rush, Timothy. "Assessing Readability: Formulas and Alternatives." The Reading Teacher. December 1985, pp. 274-283.